[MCP] LLM과 소통하는 방법: MCP(Model Context Protocol)
LLM을 쓰다보면.....
OpenAI의 ChatGPT가 출시된 이후 일상뿐만 아니라 업무에서도 LLM이 필수인 시대가 되어가고 있습니다. 초기 놀라운 기능과 함께 폭발적인 가입자를 유지했던 ChatGPT는 단 두 달 만에 MAU 1억 명을 달성했습니다.
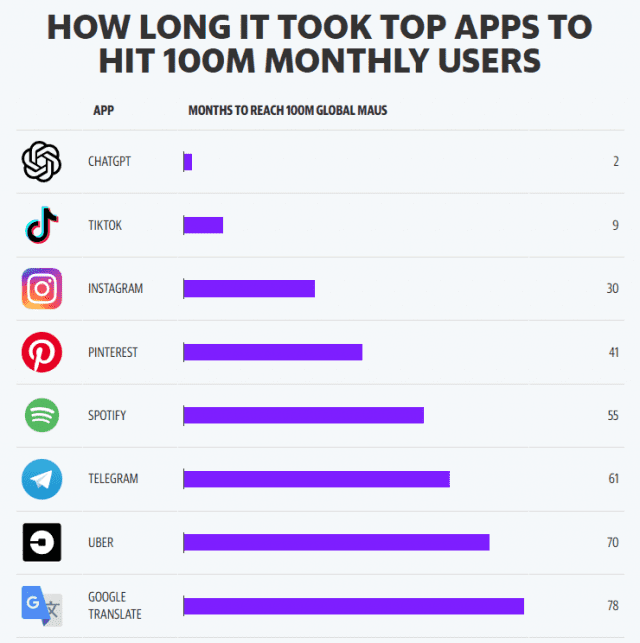
이러한 충격으로 인해 Google Gemini, facebook Llama, claude, Microsoft Copilot 등 여러 LLM 서비스들이 등장했습니다. 다만 보안 이슈를 비롯한 할루시네이션(hallucination)으로 인해서 주춤하기 시작했습니다. RAG를 비롯한 여러 기법들이 나오기 시작했지만 GPU를 비롯한 장비 수급 이슈, 저작권 등 여러 이슈들의 문제로 인해 또 한 번 주춤했었습니다. 미국 빅테크의 주총에서는 여러 성토가 있었으며, OpenAI는 천문학적인 영업손일이 예상되었습니다.

하지만 그냥 물러설 사람들이 아니죠!!(이미 들어간 돈도 너무 많습니다.....) RAG를 시작으로 정확도를 올리는 수많은 기법들이 연구되고 적용되었습니다. 그리고 거대한 모델에서 sLLM이라하는 분야별 특화된 작은 모델들이 나오고 개인 정보보호를 위한 on-device와 private cloud를 통해 보안문제도 많이 해결되었습니다. 그리고 enterprise 상품을 통해서 기업의 기밀 유출과 같은 문제점을 해결한 요금제를 출시하여 안정성도 확보하며 다시 사용자가 상승하고 있습니다. 특히 최근 지브리풍 그림을 그려주는 ChatGPT는 전 세계적인 열풍과 함께 저작권을 비롯한 많은 부분에 대한 고민점을 내놨습니다.
이러한 흐름을 크게 보면 꾸준히 우상향을 하지는 않지만, 점점 더 깊이 파고들고 있음은 확실합니다. 실제로 국내외 IT 기업들은 신규 개발자 및 3년 차 이하 개발자에 대한 채용을 확 줄였고, 그 부분을 AI가 대체하고 있습니다. 실제 저도 인턴 혹은 신입 개발자가 필요했던 업무를 AI 툴을 이용하여 쉽고 빠르게 해결하고 있으며, 평소 1주일 이상 걸리던 업무가 1~2일로 줄어드는 효과도 실제 체감하고 있습니다. 이건 나중에 다시 얘기해 볼게요!!
서두가 길었지만, 현재 LLM의 기대치는 매우 높아지고 있습니다. 그리고 이제는 이 LLM을 더 효과적으로 쓰기 위한 방법들이 연구되고 있습니다. LLM이 좋은 건 알지만 아직 사용하기엔 웹브라우저 혹은 자체 앱을 사용하는 등 나만의 에이전트를 만들거나 자동화를 하는데 아직 좀 불편한 부분이 있는 건 사실입니다.
이러한 불편함을 해소하기 위해 나온 것이 바로 MCP(Model Context Protocol)입니다.
MCP를 소개합니다!
Anthropic은 2024년 11월에 Model Context Protocol이라고 하는 AI 모델과 다양한 소스가 연동되는 방식(protocol)을 오픈소스로 공개했습니다. (Introduction the Model Context Protocol)

사실 초기에는 그다지 주목받지 못했습니다. 언제난 그렇듯 표준이 없는 분야에서는 여러 프로토콜이 선보이고 서로 표준이 되기 위한 경쟁이 치열하게 이루어집니다. 처음 관심을 받지 못하던 MCP는 2025년 초 갑자기 선풍적인 인기를 끌게 됩니다. 그 이유는 앞서 언급했던 LLM을 좀 더 효과적으로 사용하여 AI 에이전트를 만들고, 여기저기에 존재하는 API 혹은 데이터를 통일된 형식으로 LLM에 연동하고자 하는 니즈가 커지고 있기 때문입니다. 그리고 여러 커뮤니티에서 해당 방식을 선정하며 폭발적인 인기를 끌기 시작했습니다. 이 타이밍에 manus ai라는 AI 에이전트가 세상에 공개되면서 MCP에 대한 관심은 더 폭발하게 되었습니다.
사람들은 이제 다양한 source를 LLM에 연동하여 AI 에이전트를 만들고 싶어 합니다. 그리고 이러한 source들을 한대 모을 수 있는 가장 강력하며 간편한 방법이 바로 MCP입니다.
MCP 핵심 개념
MCP(Model Context Protocol)는 단순히 텍스트 프롬프트에 의존하지 않고, LLM에게 필요한 문맥(Context)을 구조화된 방식으로 전달하기 위한 표준입니다. 기존에는 “이 사용자는 누구인지”, “무슨 작업을 하려는 건지”, “지금 어떤 문서나 정보를 보고 있는지” 같은 상황 정보를 LLM에게 간접적으로 설명해야 했습니다. MCP는 이 과정을 명시적이고 일관되게 만들어줍니다.
MCP는 다음과 같은 핵심 컴포넌트들로 구성됩니다:
user – 사용자 정보
어떤 사용자인지를 LLM에게 알려줍니다. 예를 들어 사용자 ID, 역할(role), 권한 수준 등이 포함될 수 있습니다.
예시:
“user”: {
“id”: “user8461”,
“name”: “Alice”,
“role”: “editor”
}
이 정보 덕분에 모델은 사용자의 권한에 따라 내용을 필터링하거나, 사용자 맞춤 응답을 생성할 수 있습니다.
app – 애플리케이션 정보
어떤 환경에서 요청이 들어왔는지를 설명합니다. 예를 들어 kakaotalk 같은 메시징 앱인지, 내부 시스템인지 등을 명시할 수 있습니다.
예시:
“app”: {
“name”: “kakaotalk_bot”,
“version”: “1.0”
}
이는 동일한 사용자라도 다른 앱에서는 다른 응답이 필요할 수 있다는 점을 고려한 설계입니다.
message, thread, doc – 작업 및 문맥 정보
사용자가 어떤 대화를 하고 있었고, 어떤 문서를 참조하고 있는지를 포함하는 필드입니다. LLM은 이 정보들을 활용해 대화 흐름을 이해하고, 과거 맥락을 기반으로 더 정확한 응답을 할 수 있습니다.
예시:
“message”: {
“text”: “이 정책 요약해줘”,
“timestamp”: “2024-03-01T12:00:00Z”
},
“docs”: [
{
“title”: “휴가 정책”,
“content”: “전 직원은 연 15일의 연차를 사용할 수 있습니다.”
}
]
permissions – 권한 제어
LLM에게 사용자가 어떤 기능 또는 문서에 접근할 수 있는지를 알려줍니다. 예를 들어 읽기, 쓰기, 삭제 등 권한을 명시할 수 있습니다.
예시:
“permissions”: [“read”, “summarize”]
이로써 모델이 민감한 정보에 대해 오용되는 것을 방지할 수 있습니다.
retrieval – 외부 정보 연결
외부 검색 시스템에서 가져온 관련 문서나 결과를 LLM에게 전달하는 필드입니다. RAG(Retrieval-Augmented Generation) 구조에서 중요한 역할을 하며, 검색 기반 질문 응답을 가능하게 만듭니다.
예시:
“retrieval”: {
“results”: [
{ “title”: “인사 정책”, “snippet”: “연차는 연 15일 제공…” }
]
}
전체 MCP 구조 예시는 다음과 같습니다:
{
“user”: { “id”: “user4632”, “role”: “editor” },
“app”: { “name”: “intranet-assistant” },
“message”: { “text”: “휴가 규정 요약해줘” },
“docs”: [{ “title”: “휴가 정책”, “content”: “…” }],
“permissions”: [“read”],
“retrieval”: { “results”: […] }
}
이처럼 MCP는 LLM이 인간처럼 ‘상황을 이해하고 반응’하게 만드는 핵심 기술입니다. 단순한 문자열로 모델을 속이는 프롬프트 엔지니어링을 넘어서, 이제는 명시적인 문맥 설계가 중요한 시대가 되고 있습니다.
기존 방식과 MCP의 차이점
LLM을 활용할 때 대부분의 사용자들은 프롬프트 엔지니어링으로 시작합니다. 즉, 원하는 결과를 얻기 위해 텍스트를 잘 구성해서 모델에게 전달하는 방식입니다. 하지만 이 방식은 문맥이 복잡해질수록 점점 한계를 드러냅니다. 그리고 텍스트가 길어질수록 처리하는데 많은 비용 및 시간이 소요되며, 일부는 누락되는 경우도 발생합니다.
예를 들어, 사용자의 신원이나 권한, 이전 대화 흐름, 참조 문서 등 다양한 정보를 모델에게 전달하고 싶을 때, 프롬프트만으로는 구조적이고 안정적인 제어가 어렵습니다.
MCP(Model Context Protocol)는 이러한 문제에 대한 좋은 해결책이 될 수 있습니다. MCP는 LLM과의 상호작용에 필요한 문맥(Context)을 구조화된 JSON 형태로 전달함으로써, 훨씬 더 정확하고 유연한 인터페이스를 제공합니다.
기존의 LLM과의 통신(소통) 방식과 MCP의 차이점을 살펴보면 다음과 같습니다.
문맥 전달 방식
- 기존 방식: 텍스트 기반 프롬프트에 모든 정보를 문장으로 녹여서 전달
- MCP: 사용자, 앱, 문서, 권한 등을 명시적으로 구조화하여 전달
권한 및 역할 제어
- 기존 방식: “당신은 관리자인 사용자입니다”라고 명시적으로 프롬프트에 삽입
- MCP: “user”: { “role”: “admin” } 와 같은 방식으로 모델이 이해할 수 있는 구조 전달
대화 및 작업 흐름 유지
- 기존 방식: 과거 대화 내용을 프롬프트에 직접 붙여넣음
- MCP: “thread”, “message”, “doc” 등을 통해 모델이 직접 문맥을 해석
외부 정보 연동
- 기존 방식: 검색 결과나 문서를 복사하여 프롬프트에 붙여넣음
- MCP: “retrieval” 필드를 통해 외부 시스템에서 가져온 정보를 구조적으로 전달
재사용성과 확장성
- 기존 방식: 프롬프트마다 모든 내용을 반복적으로 구성
- MCP: 공통 context 구조를 모듈화 하여 반복 없이 재사용 가능
결론적으로, 전통적인 프롬프트 방식은 빠르게 시작하기는 쉬우나, 문맥이 복잡하거나 보안, 권한, 사용자 맞춤 기능이 필요한 서비스에서는 한계가 명확합니다. 반면 MCP는 명시적인 문맥 전달을 통해 LLM을 애플리케이션의 한 구성요소로 안정적으로 통합할 수 있게 해 줍니다.
이제 LLM을 “잘 쓰는 법”은 더 이상 문장을 예쁘게 만드는 것만으로는 부족합니다. 앞으로는 문맥을 어떻게 구조화하고 연결할 것인가가 LLM 활용의 핵심이 될 것입니다.
MCP.... 정리하면??
MCP에 대해서 정리하면, LLM과 더 잘 소통하기 위한 통신 규약이라고 볼 수 있습니다. USB-C라고 생각하면 좋을 것 같아요. 외장하드, 모니터, 핸드폰, 카메라, 프린터 등등 다양한 기기를 USB-C라는 통신 방식으로 통일해서 컴퓨터에 연결하는 것처럼 LLM과 그 LLM에 필요한 여러 데이터를 연동하는 하나의 방법입니다.
현재까진 가장 효과적인 방법이라고 생각합니다. 다만, 다음 달에도 이 방식이 효과적이라고 말할 수 있을지는 솔직히 모르겠네요 ㅎㅎ 하지만 방향성과 사용성 그리고 성능면에서 확실하게 좋은 기술이 나왔다고 생각합니다.
앞으로는 kakao developers의 open api를 활용하여 MCP로 ai 에이전트를 만드는 과정을 하나하나 설명해 드리겠습니다.